DiffRhythm
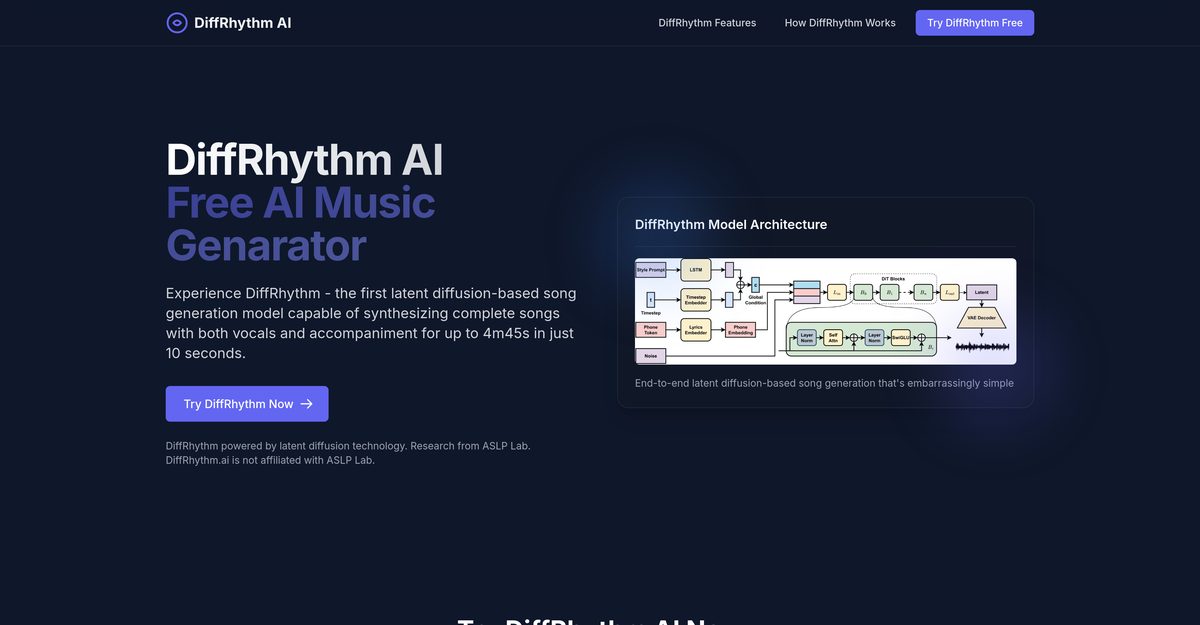
DiffRhythm is an innovative AI music generator that creates full-length songs with high-quality vocals and accompaniment in approximately 10 seconds. Utilizing advanced latent diffusion technology within a compressed latent space, it maintains musical consistency even across extended tracks up to nearly five minutes. Users can generate music across numerous genres by providing only text prompts for style and lyrics. This end-to-end architecture streamlines production, making professional-sounding audio creation accessible to both enthusiasts and commercial creators.
Pros
- Generates complete songs with vocals and accompaniment
- Rapid generation in approximately 10 seconds
- Maintains coherence and consistency across extended sequences
- Capable of producing a wide range of musical genres
- Simple user interface requiring only lyrics and style prompts
- Scalable architecture for continuous capability enhancement
- Allows commercial usage with appropriate business plans
Cons
- No option for melody or MIDI input
- Style control is limited to text-based prompts
- Potential risk of infringing on protected musical styles
- Requires manual verification of content originality
- Limited customization due to the speed of generation
- Heavily dependent on the clarity of provided lyrics
- No user control over specific accompaniment elements
- Lyric generation is not built into the tool
DiffRhythm is able to generate a complete song in roughly 10 seconds.
DiffRhythm requires only two inputs to generate a song: the lyrics and a style prompt.
Latent diffusion is a generative AI technique that works within a compressed latent space to provide higher efficiency than standard diffusion models.
Absolutely, DiffRhythm can create songs across various music genres guided by user style prompts.
Yes, DiffRhythm generates complete songs, synthesizing both vocals and the musical accompaniment.
The maximum length of a song that DiffRhythm can generate is up to 4 minutes 45 seconds.
The tool uses latent diffusion technology to maintain audio coherence across extended sequences, ensuring the song remains consistent from start to finish.
Yes, DiffRhythm offers a business plan for commercial use which includes appropriate licensing.
Currently, DiffRhythm does not offer a melody input option; the style and melody are determined by the AI based on your prompts.
Yes, it boasts a scalable architecture that allows it to be trained on larger datasets for continuous enhancement.
Become a Contributor
Sign in to unlock these features:
- ⭐️ Rate this tool with a 1-5 star score
- ✍️ Write a detailed review for the community
- ❤️ Follow this tool to get important updates
Get started in seconds
[jnews_social_login_form]